Overview
Dynin-Omni is an omnimodal discrete diffusion foundation model released by the AIDAS Laboratory. It is the first masked diffusion architecture to unify text, image, video, and speech understanding and generation within a single framework. By leveraging iterative confidence-based refinement and bidirectional token modeling, Dynin-Omni enables scalable any-to-any cross-modal generation across modalities. As demonstrated in our experiments, Dynin-Omni achieves strong and consistent performance across diverse multimodal benchmarks, validating discrete diffusion as a practical paradigm for unified omnimodal intelligence.
Capabilities
Omnimodal Discrete Diffusion
Dynin-Omni models omnimodal generation as masked token denoising over discrete sequences. Instead of autoregression, it iteratively refines masked tokens in parallel with modality-aware decoding schedules, enabling scalable and controllable generation across text, image, video, and speech.
Unified Token Space & Architecture
All modalities are mapped into a shared discrete token space and processed by a single Transformer backbone, enabling unified understanding and native cross-modal generation.

Examples
Textual Reasoning


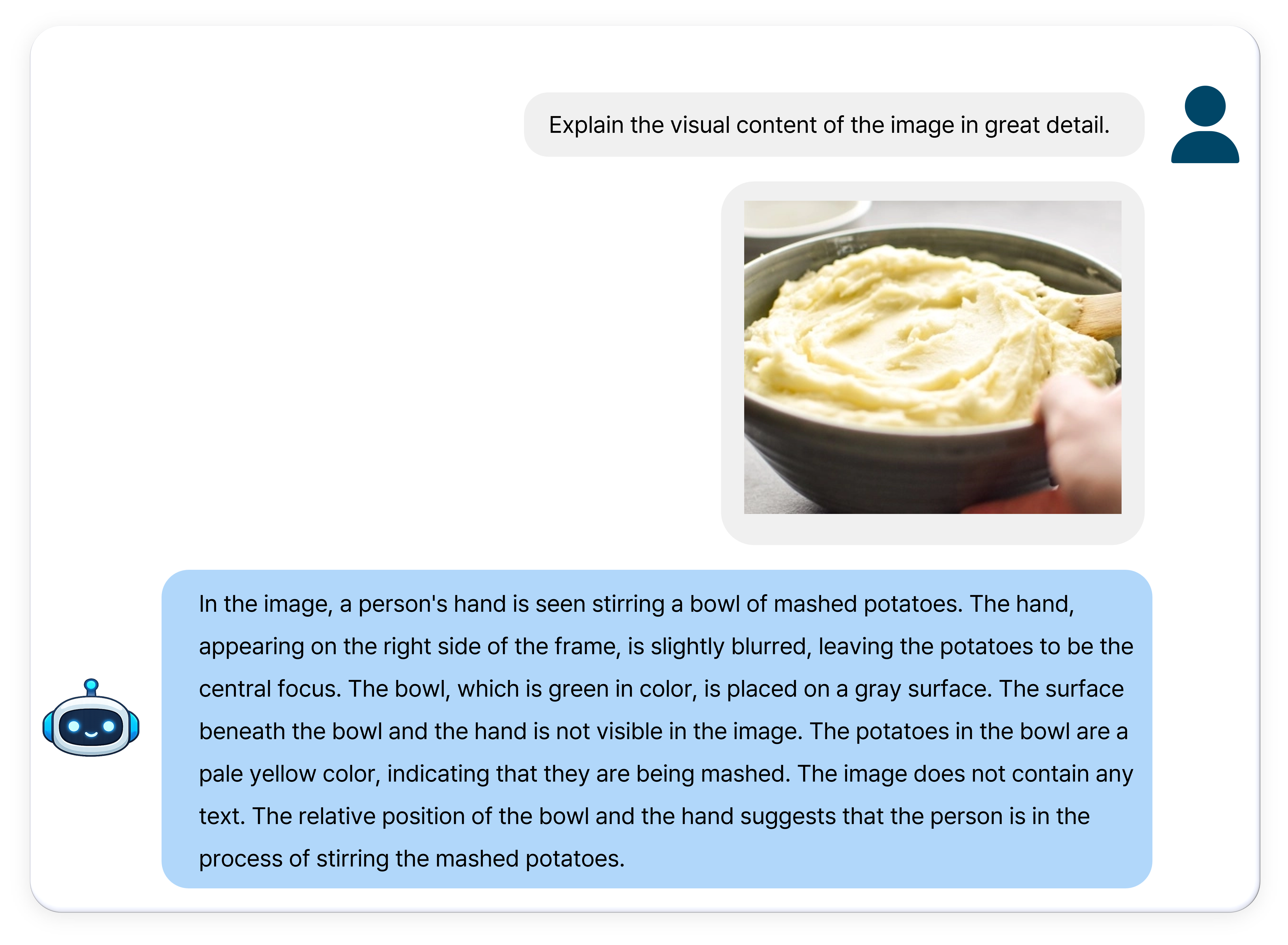
Image Understanding

Video Understanding


Image Generation




















Image Editing
ASR & TTS
Example 1 / 5
Speech → Text (ASR)

0:00
/
0:00
Text → Speech (TTS)

0:00
/
0:00
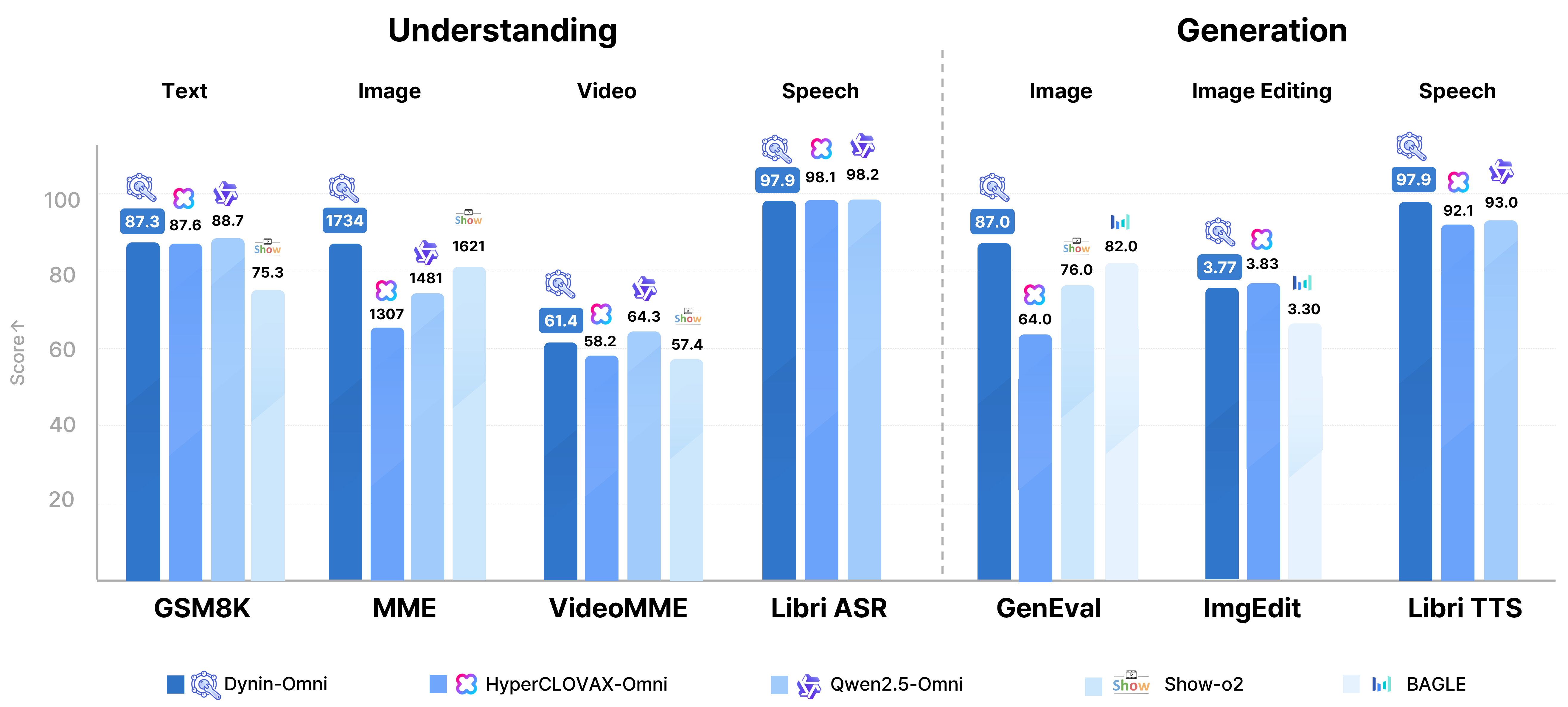
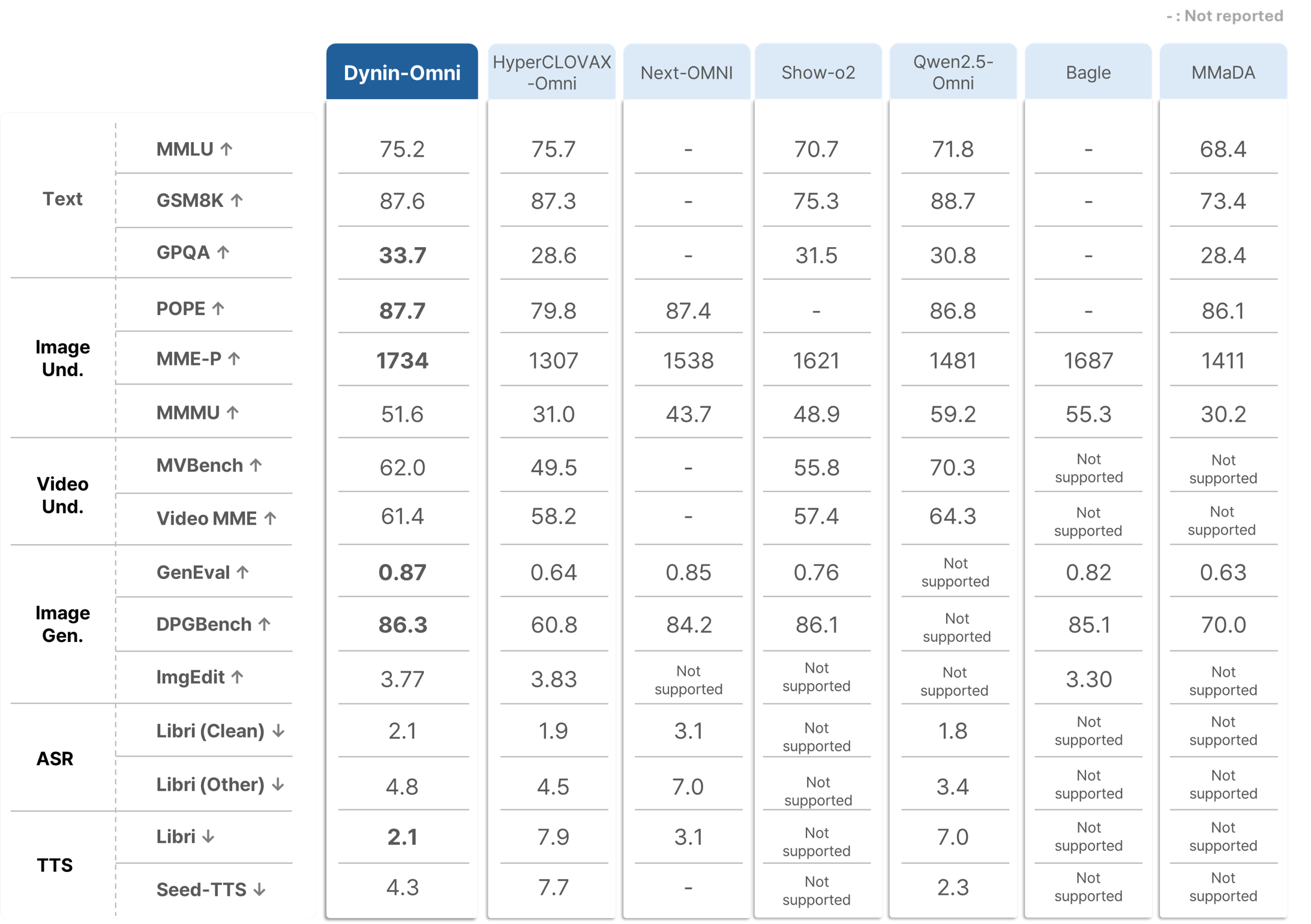
Performance
Dynin-Omni consistently achieves state-of-the-art or highly competitive results across a broad range of text, vision, video, and speech benchmarks, outperforming existing open-source unified models and narrowing the gap with modality-specific expert systems.
Contributors
Jaeik Kim
Project leader
Woojin Kim
Core contributor
Jihwan Hong
Core contributor
Yejoon Lee
Core contributor
Sieun Hyeon
Speech Team
Mintaek Lim
Video Team
Yunseok Han
Speech Team
Dogeun Kim
Model Serving
Hoeun Lee
Model Serving
Hyeonggeun Kim
Training Team
Jaeyoung Do
Supervisor